
Zum Bersten volle Kühlschränke, gähnend leere Kochtöpfe. Diese Kombination mag sich als klassisches Problem der Überflussgesellschaft qualifizieren, verweist aber auch auf ein strukturell bedingtes Selektionsproblem: jede zunehmende Möglichkeit, macht den Entscheidungsfindungsprozess schwerer. Geradezu handlungslähmend kann dieser Zustand werden, entwickelt mensch ein grundsätzliches Gefühl für den Kontrast zwischen der Fülle potentiell zugänglicher Informationen und den vereinzelten Optionskrümeln, die tatsächlich in greifbarer Nähe liegen. Was kommt also auf den Tisch, ohne der Willkür den Kochlöffel in die Hand drücken zu müssen?!
Ein Weg sich dieser Frage anzunehmen, wäre vermutlich ein Blick auf die chemische Struktur von Lebensmitteln zu werfen. Nun bin ich aber Soziologe und meine Kenntnisse der Chemie beschränken sich weitgehend auf Quizduell und den ein oder anderen SciFi-Streifen. Abgesehen davon dürfte angesichts des neuen Staatsschutzgesetzes der Zeitpunkt ohnehin schlecht gewählt sein, sich ein Labor und die passenden Chemikalie anschaffen zu wollen. Bleibt also nichts anderes übrig, als auf die feinen Gaumen meiner Mitmenschen zu vertrauen und zu hoffen, dass sich die Fragestellung dadurch lösen lässt.
Rückblickend betrachtet ein recht pragmatischer, aber überraschend effizienter Weg das Problem des leeren Kochtopfes zu lösen, ohne dabei auf Strich und Punkt den Anweisungen eines Rezepts folgen zu müssen. Meine Strategie im Hinterkopf, durchforstete ich 14.801 Rezepte eines Onlinekochbuchs, notierte und bereinigte die auftretenden Zutaten und erstellte daraus ein Netzwerk. Eine Verbindung im Netzwerk gingen all jene Zutaten ein, die im ein oder anderen Rezept gemeinsam miteinander vorkamen. Mit der Annahme, dass ein gemeinsames Auftreten von Zutaten auf eine Geschmackssymbiose hindeuten könnte, wurde – bei einem einfachen Rezept für Tomatensauce – etwa eine Verbindung zwischen Tomaten, Knoblauch, Zwiebeln, Olivenöl, Salz, Pfeffer, Thymian, Oregano, Rosmarin und Basilikum gezogen. Ein wenig Arbeit und einen knurrenden Magen später, formierte sich dieser Grundgedanken zu einem ausgewachsenen Netzwerk mit 3.554 Zutaten/Knoten und 133.548 Verbindungen.
In den folgenden Abschnitten geht es erst um die Erhebung und Bereinigung der Daten, bevor ein Blick ins Herz der Kulinarik gewagt und eine Antwort darauf gesucht wird, welche Zutaten außergewöhnlich häufig miteinander in einem Kochtopf schwimmen oder wie sich der Kühlschrank leeren lässt, ohne den Magen dabei all zu sehr zu verstimmen.
Sammeln der Zutaten
In einem ersten Schritt setzte ich (m)einen Crawler in R auf. Ausgehend von der Auflistung aller vorhandenen Rezeptetitel des Onlinekochbuchs, sammelte der Crawler die passenden Links zu den jeweiligen Kochanleitungen. Die einzelnen Links wurden danach schrittweise angesteuert und Informationen zu den vorhandenen Zutaten, den passenden Mengenangaben, der Kochdauer, der Anzahl der Zugriffe, der Klassifizierung, sowie zu Portionsangaben, Schwierigkeitsgrad und zur Rezeptbewertung wurden gesammelt. Um dabei niemandem auf die Zunge zu treten, ließ ich nach jedem angesteuerten Link zumindest zwei Sekunden verstreichen. Ohne die verstrichene Zeit gemessen zu haben, dürfte diese Sammelaktion gute neun Stunden beansprucht haben.
Das Sammeln der Zutaten funktionierte überraschend gut und auch die ersten Erkenntnisse ließen nicht lange auf sich warten.
Die fünf meistgesuchten Rezepte sind Palatschinken (mit 1,3 Mio. Aufrufen), Spargel (1 Mio.), Tiramisu (830.318), Semmelknödel (787.440) und Vanillekipferl (711.891). Da – bis auf die Vanillekipferl – all diese Rezepte eigentlich ein recht intuitives Vorgehen erlauben und nicht all zu komplex sind, spekuliere ich mal, dass diese Suchanfragen häufiger von Jungköch*innen und seltener von den kochroutinierten Omas und Opas gestellt werden. Unabhängig davon gebe ich aber zu, das Palatschinkenrezept selbst je aufs Neue heraussuchen zu müssen.
Dem Schwierigkeitsgrad nach, finden sich vorwiegend einfache (29,13 %) und mittelschwere Rezepte (64,19 %). Ein Blick in die Trickkiste von Profi-Köchen (6,75 %) darf daher nicht erwartet werden
Finden sich in einem Rezept keine Angaben dazu, für wie viele Personen die Mengenangaben gedacht sind, lässt sich die passende Portionierung durch eine Melange Bauchgefühl und Statistik in 84,35 % der Fälle recht zuversichtlich schätzen: 60,66 % der Rezepte sind für vier Personen kalkuliert, 11,32 % für zwei, 7,39 % für sechs und 4,98 % für eine Person.
Ein 5-Sterne-Bewertungssystem ist wenig hilfreich, wenn 87,24 % der Rezepte mit vier Sternen bewertet werden.

Ein durchschnittliches Rezept umfasst 10 explizit aufgelistete Zutaten.Während die mittleren 50 % der Rezepte zwischen 8 und 14 Zutaten beinhalten, zeigt sich insgesamt eine rechte Variationsbreite zwischen 1 und 41 Zutaten. Rezepte mit mehr als 20 Zutaten sind – wenig verwunderlich – meist etwas gefinkelter als Palatschinken. Gleichzeitig wird dieselbe Zutat mitunter in verschiedenen Kochzusammenhängen angeführt: Butter zum Ausfetten der Backform und Butter für den Teig. Rezepte mit einer Zutat befassen sich demgegenüber mit der grundsätzlichen Frage der Zubereitung eines speziellen Lebensmittels (etwa mit dem richtigen Brechen und Kochen von Spargel).

Veredelung der Zutaten
Die größte Herausforderung bei diesem kleinen Projekt, war die Bereinigung der gesammelten Zutaten: das Angleichen der Schreibweisen, die Gruppierung von all zu ausgefallenen oder synonymen Zutaten, das löschen überschüssiger Bezeichnungen mit beschreibend-ergänzendem Charakter und das Ausmerzen lästiger Markennamen. Das Ziel bei diesem Vorgehen war, das Netzwerk auf die relevantesten Zutaten zu reduzieren ohne durch einen zu hohen Abstraktionsgrad die Möglichkeit zu verlieren, interessante Zusammenhänge ausfindig zu machen. Die ursprünglich fast 9.000 verschiedenen Zutaten wurden in diesem Schritt auf 3.554 Klassen zusammengeführt.
Um das Zuordnungsproblem zu lösen, versuchte ich mit Google Refine und verschiedenen Fuzzy Match Algorithmen ähnliche Zutatenbezeichnungen zu finden. Während damit ein recht komfortables Leitsystem durch das Chaos verschiedener Schreibweisen gefunden wurde, war ein wirklich automatisiertes Vorgehen meist nicht möglich und eine Angleichung erfolgte weitgehend nach Augenmaß und Bauchgefühl. Zwar wurde ein Abänderungskatalog erstellt, der Katalog fasste aber mehr eine (lange) Reihe an Spezialfällen und maßgeschneiderten Einzellösungen und weniger eine systematisch generalisierbare Angleichungen.
Exemplarisch festgehalten wurde(n) in diesem Arbeitsschritt Suppen-Gemüse zu Suppengemüse, die Marmelade zur Konfitüre und Zitronenzesten zur Zitronenschale. Bezeichnngen wie “zum Braten”, “ganze”, “andere” oder “angedrückt” wurden ebenso wie Überbleibsel von Mengenangaben gelöscht und ein bekannter Brotaufstrich wurde seines Logos beraubt und zum schlichten Frischkäse Doppelrahm degradiert. Gleichzeitig blieb aber der Apfel Apfel und wurde nicht zum abstrakteren Obst. Beim Zusammenführen unterschiedlicher Abstraktionsniveaus orientierte ich mich an der Häufigkeit des Auftretens einzelner Zutaten. Sehr spezielle Zutaten mit häufigem Auftreten wurden als eigene Klasse belassen, während andere – mit seltenem Auftreten – in abstraktere Klassen zusammengefasst wurden. Bedingt durch dieses uneinheitliche Vorgehen und unterschiedlich genaue Spezifikationen in den Urrezepten, ergaben sich teils unsaubere/überlappende Zutatenklassen. So kommen im Netzwerk sowohl Beeren, als auch Erdbeeren vor. Um nicht gezwungen zu sein auf das kleinste gemeinsame Vielfache zurückzugreifen und ein Netzwerk aus Öl, Fleisch, Fisch, Getreide, Beeren und Gemüse zu kreieren, wurde diese Unschärfe bewusst in Kauf genommen.
Etwas systematsicher konnten andere Aufgaben der Datenbereinigung gelöst werden. In weiteren Schritten wurden (vertauschte) Zutaten in der Mengenspalte bzw. Mengenangaben in der Zutatenspalte korrigiert. Zutatenketten in einer Datenzeile (“Salz, Pfeffer”) wurden anhand von einem Trennzeichen- und Bindewortkatalog in je eigene Datenzeilen aufgesplittet. Vereinzelt kamen auch ganze Rezepte als Zutat vor (Blätterteig Grundrezept). In diesen Fällen wurden die Zutaten dieser (Grund-)Rezepte in das neue Rezept integriert. Fehlerhafte Links wurden in diesem Schritt bereinigt. Mengenangaben flossen nicht in die Netzwerkstruktur ein und Zutatenduplikate innerhalb eines Rezepts wurden abschließend gelöscht.
Erkenntnisse im Rahmen der Zutatenbereinigung
Leute, die Rezepte verfassen lieben lokale Couleur und erkennen die nötigen Zutaten in einer spielerisch-lieblichen Sprache an. In der Regel wird dabei der Wirsing zum Kohl und der Kohl – wie schon das Schweinshaxerl oder das Wangerl – zum Köhlchen. Ob diese Verniedlichung – gerade bei Fleisch – den nötigen Ausgleich schafft, den doch etwas brachialeren Akt der Schlachtung, das Spritzen von Blut und das Entleeren des Darms vergessen zu machen? Ich weiß es nicht. Ein Schweinshaxerl ist für meinen emotional empfindlichen Magen jedenfalls leichter verdaulich, als der abgehackte Fuß einer (nunmer) dreibeinigen, verstümmelten Sau.
Verwandt mit Punkt eins: Essen erdet. Und das liegt nicht nur daran, dass vieles Essen in der ein oder anderen Form aus der Erde stammt. Vielmehr erdet auch die Sprache. Verfasser*innen von Kochideen reproduzieren diesen Zusammenhang, indem das Bio im Ei und die Natur im Kraut explizit hervorgehoben werden. Kurz: Romantisierung als heimliche Würze gegen den fahlen Geschmack von Technisierung und Kultivierung. Wer will heute schon noch Kräuter aus dem Glashaus?
Damit will ich mich nicht über die Verfasser*innen der Rezepte lustig machen (bei der devianten Salat-mit-Ketchup-Fraktion behalte ich mir dieses Recht aber vor). Ganz im Gegenteil: Kochrezepte eröffnen einen spannenden Einblick in die gesellschaftliche Seele der Kulinarik. Ob das die Chemie auch erfasst hätte? Vielleicht über ihr soziologisches Unterbewusstsein. Ich freue mich jedenfalls schon jetzt dazu mal die ein oder andere Analyse in die Finger zu bekommen.
Im Anschluss an diesen mühsamen Prozess der Datenbereinigung, folgte die weitaus spaßigere, netzwerkanalytische Aufbereitung. Im nachfolgenden Teil werden dabei zwei Fragen adressiert:
- Was lässt sich über die Struktur von Kochrezepten sagen? Wie viele Zutaten finden sich in einem Rezept, wie viel potentielle Zutaten hat eine durchschnittlich gesellige Zutat, gibt es allgemeine Grundzutaten, die in keinem Rezept fehlen dürfen und lassen sich Gruppen von Zutaten identifizieren, die speziell für bestimmte Gaumen und Anlässe gedacht sind?
- Wie fülle ich mit diesem Metawissen meinen Magen? Was koche ich heute Abend?
Der netzwerkanalytische Kochtopf
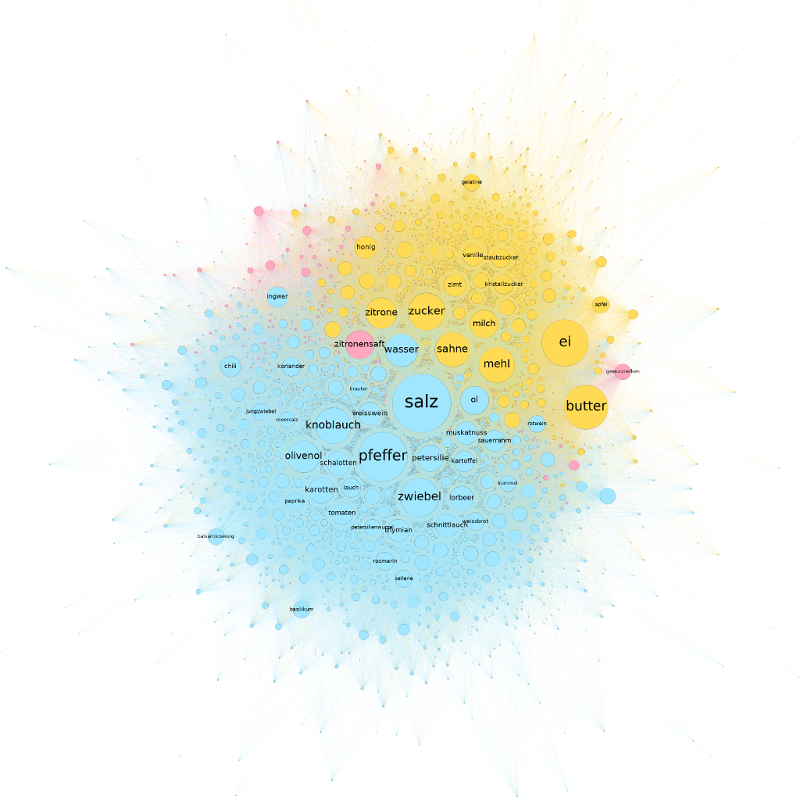
Nach sparsamem Wegschneiden der schlechtesten Zutaten, blieben von den ursprünglich über 9.000 verschiedenen Ingredienzen gerade mal noch 3.554 übrig, die untereinander aber 133.548 Verbindungen eingingen. Über alle Rezepte hinweg, köchelte eine durchschnittliche Zutat mit etwa 75 anderen Zutaten in einem Topf. Um genau zu sein: in mehreren verschiedenen Töpfen. Ein Blick unter den Deckel ließ fünf Basiszutaten an die Oberfläche treiben: Salz (mit 2.747 Verbindungen zu anderen Zutaten), Pfeffer (2.300), Ei (2.162), Butter (2.053) und Zwiebeln (1.796). Ein genauerer Blick auf die Struktur des Netzwerks zeigt recht dichte Verbindungen: der Diameter – also der längste Weg zwischen zwei Knoten, ohne dabei unnötig zu schlendern – betrug vier. Lebensmittel hegen damit scheinbar engere Beziehungen, als wir Menschen. Vermutlich hat das damit zu tun, dass die meisten von ihnen schon vor langer Zeit kultiviert wurden.
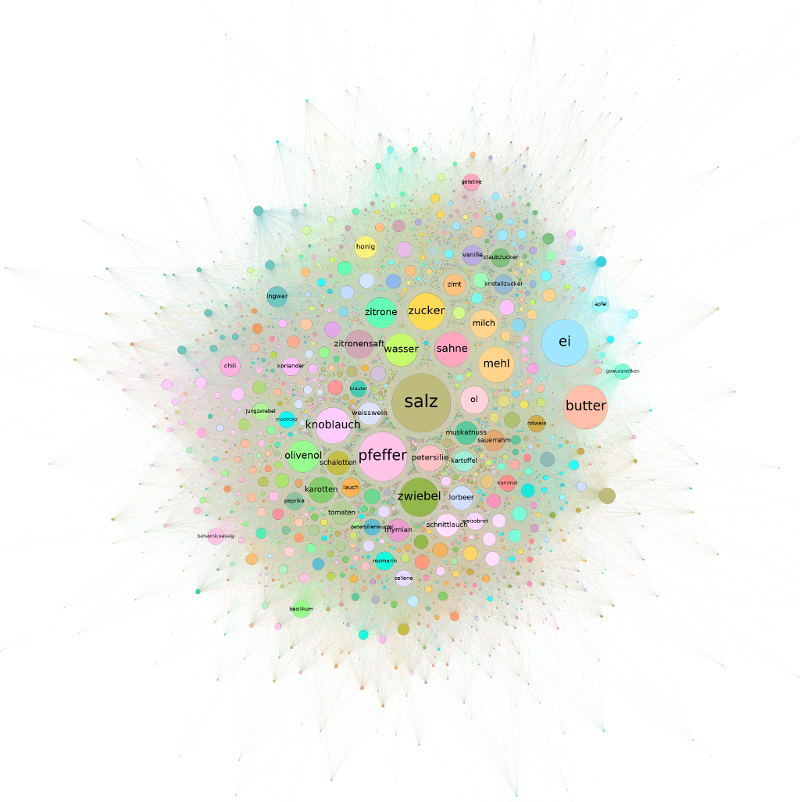
Betrachtet mensch jedenfalls das so entstandene Netzwerk danach, welche Zutaten sich gemeinsam auf einen Haufen hauen, helfen Modularitätsklassen dabei etwas Struktur in Ganze zu bringen. Modularitätsklassen identifizieren – je nach definierter Resolution – größere bzw. kleinere Gruppen im Netzwerk, die miteinander eine besonders enge Beziehung aufweisen. Bei einer Resolution von 1.0 lassen sich so etwa 8 Zutatengruppen erkennen (von denen die drei größten zusammen gut 99 % aller Zutaten fassen). Nach dieser Gruppierung teilt sich das Netzwerk – trotz einer etwas unsauberen Schnittkante – in zwei Haufen. Im Größten (53,74 %) finden sich Zutaten wie Salz, Pfeffer, Zwiebeln oder Knoblauch. Im Zweiten (35,93 %) Ei, Butter, Zucker, Mehl oder Sahne. Der Kleinste (9,76 %) ist ein Gewirr aus Zitronensaft, Gewürznelken, braunem Zucker, Portwein, Kokosmilch, Sternanis oder Ananas. Lassen wir die dritte Gruppe vorerst unter den Tisch fallen, könnten wir behaupten es handle sich hier um salzige und süße oder um Koch- und Backzutaten.
Während sich Feinspitze damit vermutlich nicht so einfach abspeisen lassen, verwöhnt eine Resolution von 0,1 den Gaumen Datenhungriger mit deutlich mehr Nuancen. Hier treten nämlich 123 verschiedenen Zutaten-Gruppen hervor. Die Gruppen fassen höchstens 3,46 % und zumindest 0,06 % der Knoten zusammen. Auf den ersten, das Gesamtbild fassenden Blick, verlieren wir so zwar Struktur. Wenn wir auf dieser Basis aber tiefer ins Netzwerk reinzoomen, ermöglicht es uns diese Auflösung deutlich spezifischere Aussagen über unser Netzwerk zu treffen. So fassen die zehn größten Cluster etwa ein Viertel aller Zutaten. Mit einem Blindgriff in die Zuckerdose lassen sich die größten Gruppen als Mix zwischen Weltküchen und Rezepttypen beschreiben. Wobei das Andere das Eine ja nicht unbedingt ausschließt.
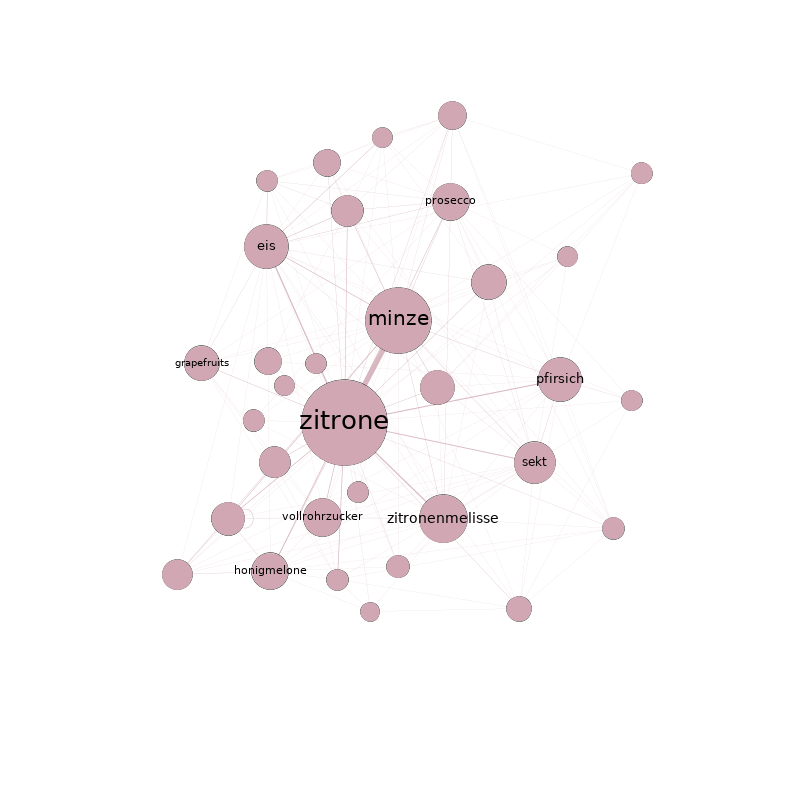


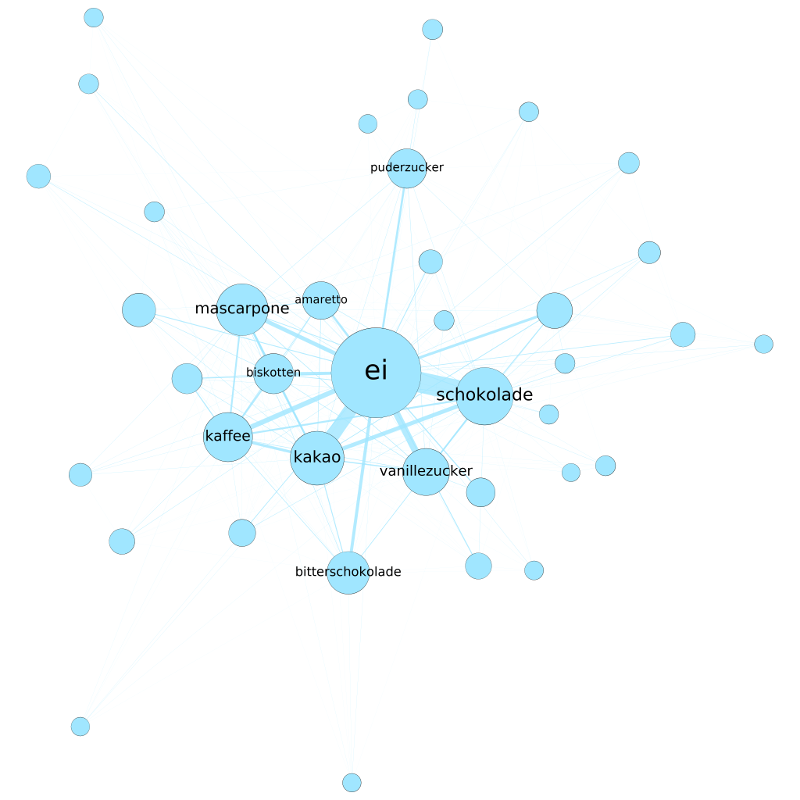
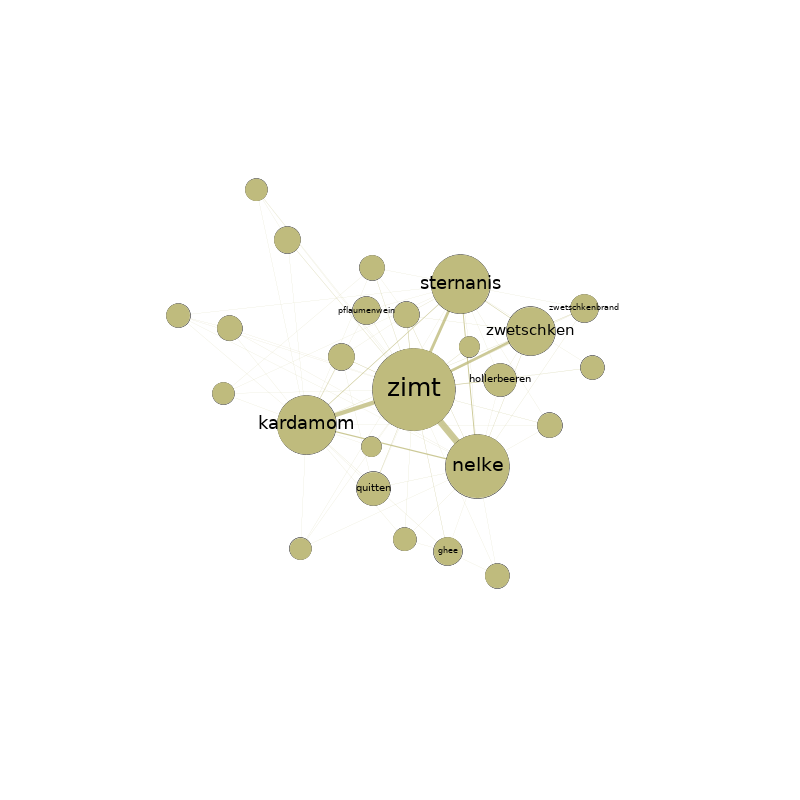
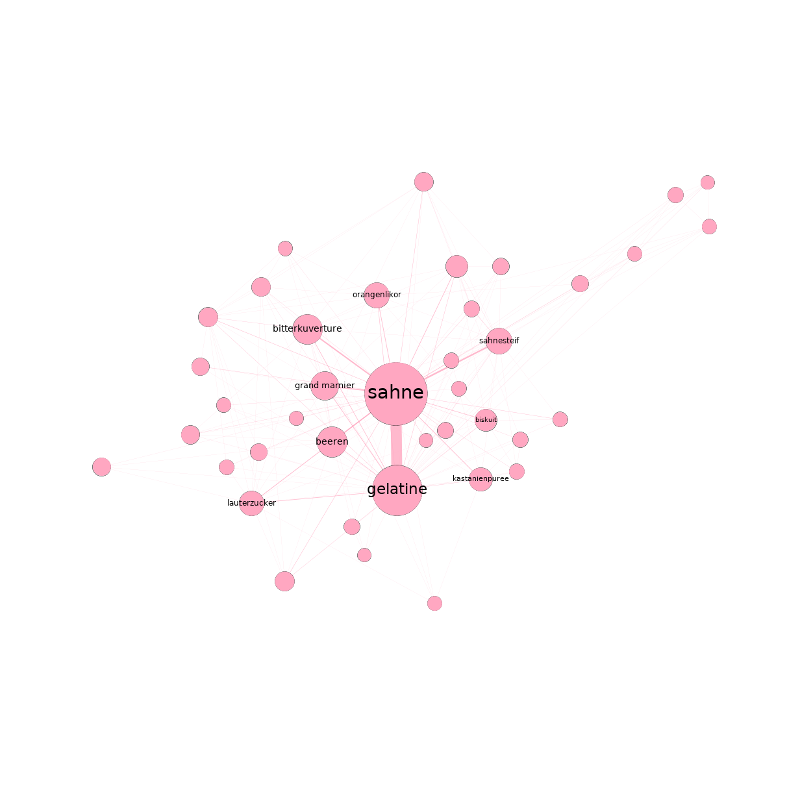
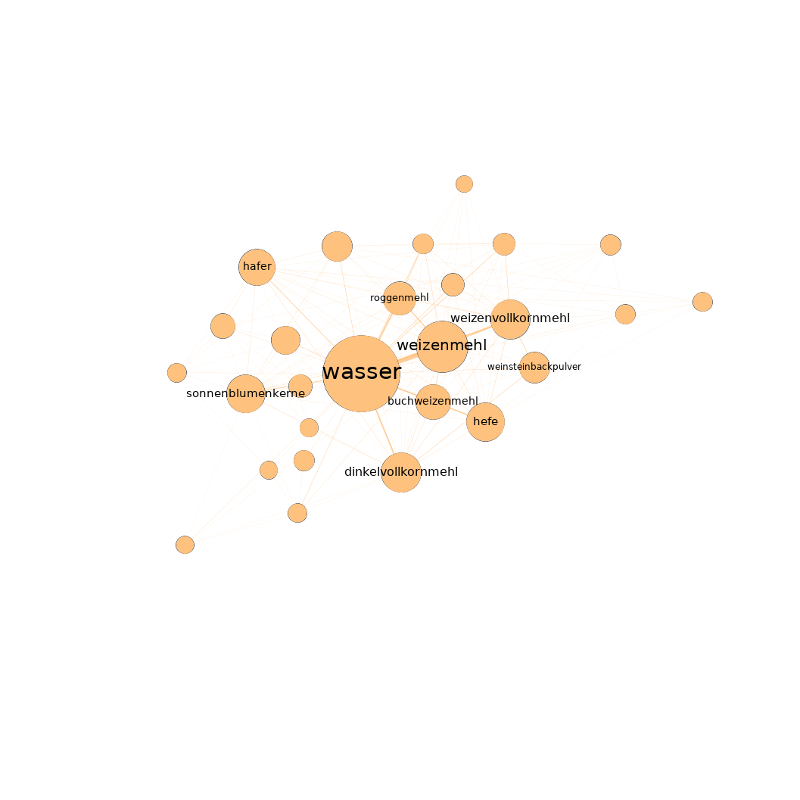
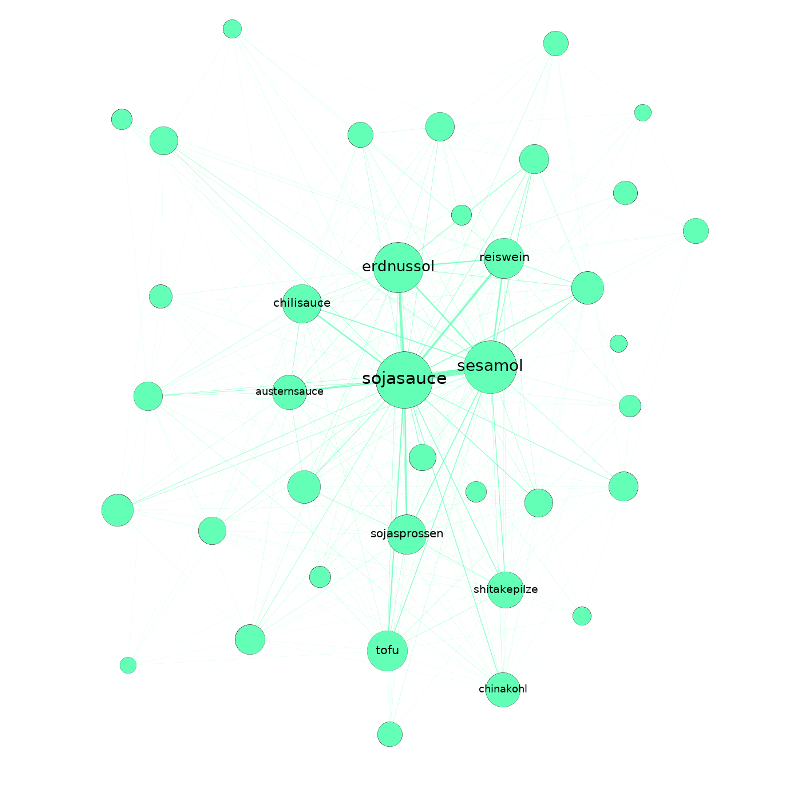
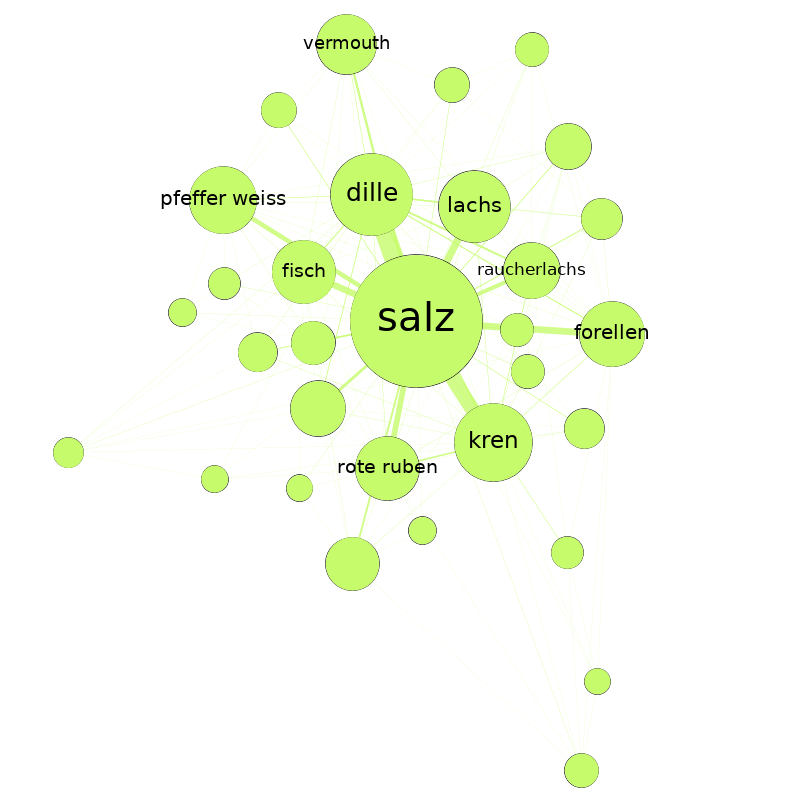
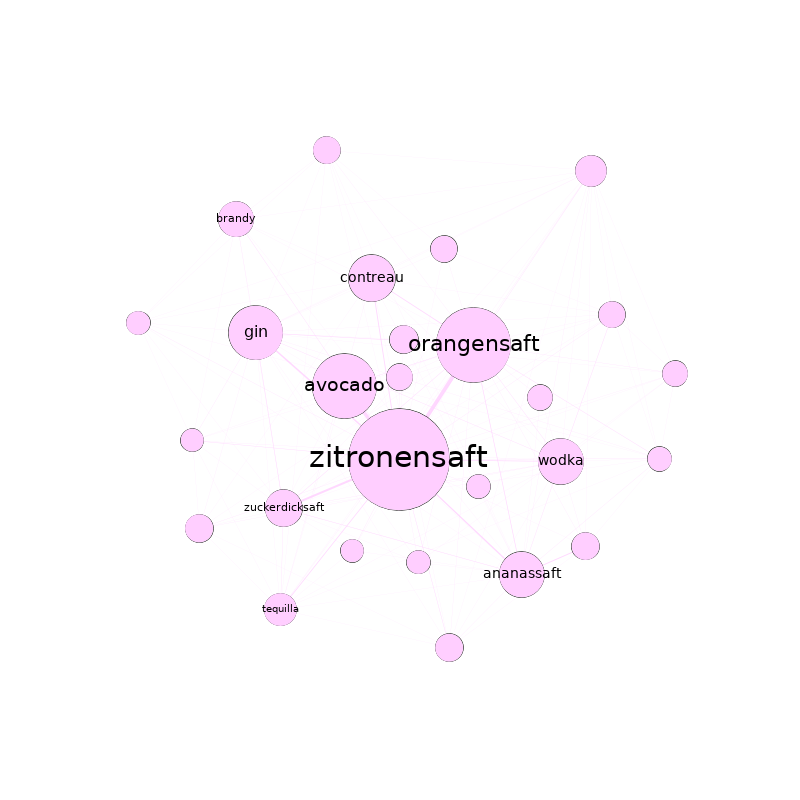
Gruppenübergreifend lassen sich mit der Betweenness-Zentralität auch eine handvoll Basiszutaten identifizieren, die in keinem Rezept fehlen sollten: Salz, Pfeffer, Eier, Butter und Zwiebeln. Damit dürfte Eierspeis hier wohl erstmals wissenschaftlich fundiert zur Mutter aller Rezepte gekürt worden sein. Auf der Spitze ihrer Zungen konnten die ein oder anderen den Geschmack dieses Sieges aber wohl schon seit langem erahnen.
Der Rezeptgenerator
Um nach der Ausarbeitung dieses schönen, aber schwer kaubaren Rezeptwissens nun auch hungrige Mäuler stopfen und knurrende Mägen zum Verstummen bringen zu können, bedurfte es eines anderen Zugangs. Nämlich dem eines Rezeptgenerators. Auf Basis einer Adjazenzmatrix wurden ausgehend von einer Startzutat in einem Schritt erreichbare Nachbarzutaten gefiltert. Die Nachbarzutaten wurden nach der Häufigkeit des gemeinsamen Auftretens mit der Startzutat sortiert und eine der gefilterten Zutaten wurde in das Rezept aufgenommen. Im nächsten Schritt wurden auf diese Weise die Nachbarzutaten der ausgewählten Nachbarzutat gesucht etc.
Da das aber zu unbestimmbaren und Magen verstimmenden Kochvorschlägen führte, wurde der Nachbarschaftsbegriff erweitert. Die echten Nachbarsknoten wurden um die gesamten Nachbarsknoten aller vorheriger Zutaten ergänzt. Um Zutaten häufig gekochter Rezepte nicht überproportionalen Einfluss zu geben, wurde die (absolute) Häufigkeit des gemeinsamen Auftretens in eine relative Häufigkeit verwandelt. Die einzelnen Bedeutungsgewichte für jede Zutat wurden dann summiert. Zutaten mit den höchsten Bedeutungsgewichten bildeten die Basis für die weitere Selektion. Mit dem Verdacht, dass die nach wie vor aufblinkende Zutatenanarchie mit dem hohen Einfluss des aktuellen Knoten zu tun haben könnte, wurde der Einfluss neuer Knoten vorerst begrenzt, indem deren Bedeutungsgewicht mit einem Anteil von 0.3 in die summierte Bedeutung einfloss, während die Bedeutung der vorangegangenen Knoten mit 0.7 gewichtet wurde. Um das Selektionsverfahren dann aber doch noch etwas aus diesem engen Korsett zu befreien und den Geschmacksknospen gelegentlich auch eine Überraschung zu gönnen, wurde zufällig eine der top-x Verbindungszutaten gewählt.
Schien eine Zutat A über alle Rezepte hinweg beispielsweise 100 mal auf und stand dabei 12 mal in Verbindung mit Zutat C, wurde C eine zwölfprozentige Bedeutung für die Rezeptgestaltung A zugesprochen. Kam Zutat C nun gleichzeitig auch eine 17 prozentige Bedeutung für die Rezeptgestaltung B zu und waren sowohl A und B Zutaten eines generierten Rezepts, wurde der Zutat C für das neue Rezept ein Bedeutung von 29 % zugesprochen. Da der Einfluss gewichtet wurde, stimmt diese Rechnung aber natürlich nicht ganz. Um genau zu sein, kam der Zutat C in diesem Beispiel eine gewichtete Bedeutung von 13,5 % zu (0,12*0,7 + 0,17*0,3).
Um den nachfolgenden Code für den Rezeptgenerator nachvollziehbarer zu gestalten, hier ein beispielhafter Auszug aus der Zutaten-Adjazenzmatrix. Die Zeilennummern entsprechen der Reihenfolge der Spaltennamen. Zeile vier fasst also alle Verbindungen zwischen Eis und anderen Zutaten. Die Zellwerte beschreiben die absolute Auftrittshäufigkeiten. Im gewählten Auszug tritt Eis also zwölfmal in Erscheinung und geht dabei acht Verbindungen mit Orange(n) ein. Da es sich um ein ungerichtetes Netzwerk handelt, ist die Matrix über die Achse gespiegelt (Orange tritt also auch achtmal mit Eis in Erscheinung). Durch die Duplikatsbereinigung wurden auch Loops (Eis auf Eis) gelöscht, weswegen die Matrix diagonal mit Nullen befüllt ist.
| X1757.cinzano.rosso | bankes | campari | eis | orange | |
|---|---|---|---|---|---|
| X1757.cinzano.rosso | 0 | 1 | 1 | 1 | 1 |
| bankes | 1 | 0 | 1 | 1 | 1 |
| campari | 1 | 1 | 0 | 2 | 3 |
| eis | 1 | 1 | 2 | 0 | 8 |
| orange | 1 | 1 | 3 | 8 | 0 |
Um das ganze auch testen zu können, hier ein kurzer Code-Schnipsel, der die benötigten R-Packages, die Beispielmatrix, die Funktion für den Rezeptgenerator und mehr Kommentare als Code enthält.
Fünf Vorschläge für heute Abend
Ausgehend von einer zufällig gewählten Startzutat habe ich den Generator getestet und fünf Rezepte erstellen lassen. Die ein oder andere Kreation mag nach mutigen Mündern und kräftigen Mägen verlangen, grundsätzlich landeten aber durchwegs essbare Kombinationen im virtuellen Kochtopf.
Sollten Silberohren Pilze sein. Ich bin aber auch bereit, das gegen eine Fischpfanne Asia auszutauschen. Am Asia halt ich – als Kind der Supermarkt-Ethno-Produkt-Ecke – fest. Da führt kein Weg dran vorbei.
Silberohren, Sojasauce, Sesamöl, Öl, Jungzwiebeln und Lauch
Wenn der Speck am Brot nicht schon genug ist oder der zaghafte Versuch sich mit vegetarischer Ernährung auseinanderzusetzen im Herzen glimmt, scheint mir das ein durchaus kaubarer Happen.
Rohschinken, Ei, Pfeffer, Balsamicoessig, Rucola, Zwiebeln, Schnittlauch
Ich gebe zu, damit bin ich überfordert.
Kürbiskernmehl, Topfen, Butter, Mehl, Pfeffer, Zwiebel, Muskatnuss
Nach einer durchzechten Nacht gilt es die Batterien wieder aufzuladen. Der Anti-Kater-Drink bietet dabei nicht nur eine geschmackliche Explosion, sondern auch Vitamine, Energie, die ganze Liebe der Butter und die antibakterielle Kraft der Zwiebel. Gerade nach einer Nacht als Rockstar sollte mensch letzteres nicht aus den Augen verlieren.
Mangodicksaft, Orangensaft, Zitronensaft, Kristallzucker, Butter, Salz, Zwiebel
Die Vorzüge verschiedener Weltküchen schlicht in einem Gericht vereint. Das Lorbeerblatt allein streicht hier schon die Bedeutung dieser Kreation hervor.
Sacherwürstel, Knoblauch, Paprikapulver, Zwiebel, Butter, Kümmel, Lorbeer
Auf einem warmen Grießbett ruhend und mit Pfeffer bezuckert, sehnt sich die süß-säuerliche Geleemasse darauf unsere Gaumen mit einer Geschmacksexplosion zu sprengen.
Orangenhonig, Agar-agar, Zitronensäure, Zucker, Butter, Pfeffer, Weizengrieß
Was noch bleibt …
Auf den ersten Blick scheinen die Rezepte durchaus kochbar. Wenn der Fruchtsaft mit Zwiebeln, Butter und Salz auch eher etwas für Experimentierfreudige sein dürfte.
Die Analyse der Netzwerkstruktur und die Clusterbildung halfen dabei, einzelne Weltküchen bzw. unterschiedliche Kochzusammenhänge bestimmen zu können. Eine Info, die auf den ersten Blick als Spielerei für Liebhaber*innen gewertet werden könnte. Neben einem allgemeinen Smalltalk-Wert lässt sich durch diese Einblicke aber auch die Funktion des Rezeptgenerators verbessern. Die relativ intuitive Herangehensweise des Rezeptgenerators liefert – mit Ausnahmen – recht stimmige Kreationen.
Freilich hinkt der ganze Ansatz (noch) auf beiden Beinen. Je mehr Zutaten in das Rezept aufgenommen werden sollen, desto gewagter werden die Kreationen. Besonders die Grenze zwischen Koch- und Backzutaten beginnt in solchen Situationen langsam zu verdampfen. Da ein Rezept mit 3.554 unterschiedlichen Zutaten zwingend alle Knoten des Netzwerks einschließen würde, liegt dieses Problem zwar in der Natur der Sache, es bleibt aber die Frage, wie dieser systematischen Geschmacksverwirrung möglichst lange entgegengewirkt werden kann. So könnte noch mehr Gewicht auf gemeinsam geteilte Zutaten zwischen den ausgewählten Rezeptkomponenten gelegt werden. Auch die Ergänzung um weitere Klassifizierungsdimensionen wie süß, sauer, Suppe, Hauptspeise, Fleisch, Fisch, vegetarisch etc. wäre eine Möglichkeit den “Charakter” eines Rezepts besser einzugrenzen und zu bestimmen. Zutaten mit der selben Klassifizierung würden dann bevorzugt oder die Suche würde gleich rein auf das jeweilige Cluster eingegrenzt.
Zutatenklassifizierungen wurden auch auf einer anderen Ebene zum Problem: beispielsweise die gemeinsame Auswahl von Butter, Öl, Erdnussöl etc. in einem Rezept. In einigen Fällen mag das zwar Sinn ergeben, die Mehrzahl der Rezepte dürfte aber mit einer gewissen Höchstanzahl bestimmter Produktgruppen auskommen. Die Frage ist also, wie sich die Verteilung einzelner Produktgruppen (Gewürze, Kräuter, Bratmittel, Haupt-/Nebenzutate) über die Rezepte hinweg beschreiben lässt. Ein generiertes Rezept sollte sich grundsätzlich an dieser Verteilung orientieren und beispielsweise nur Butter oder Öl, aber nicht beide Zutaten in das Rezept mit aufnehmen.
Die Feingliedrigkeit der Zutatenelemente führt zu einer relativ großen Adjazenzmatrix (3.554 x 3.554), die Verbindungen zwischen Zutaten durch gut zwölf Millionen Einträge beschreibt. Das Finden von passenden Zutatenkonstellationen aus diesem Wirrwarr an Informationen dauert eine gewisse Zeit. Für die Kreation eines Rezepts mit sieben Zutaten, müssen etwa 30 Sekunden totgeschlagen werden. Werden die Lösungsansätze von zuvor noch mitgedacht, ist anzunehmen, dass die benötigte Zeit merklich ansteigen wird. Um das zu umgehen, wäre eine weitere Reduktion der Zutatenvielfalt zu überlegen, die Anschaffung eines zeitgemäßeren PCs und vor allem die Überarbeitung der Rezeptgenerator-Funktion. Da ich mitunter etwas umständlich an die Dinge herangehe, bin ich sicher, dass sich diese noch merklich beschleunigen lässt.
Abgesehen davon bleibt – angesichts der aktuellen Uhrzeit – nicht viel anderes übrig, als nach diesen theoretischen Überlegungen einen Feldversuch zu wagen und mich auf den nächsten Kochtopf zu schwingen.

Leave A Comment